논문의 저자
Jeffrey Pennington, Richard Socher, Christopher D. Manning(2014)
들어가기에 앞서
논문을 참고하며 작성한 글로, 잘못 이해한 부분이 있을 수 있습니다. 참고 바랍니다.
논문 요약
Word vector representation에 대한 연구가 지속되고 있고, 최근 여러 모델들이 벡터 연산으로 미세한 semantic, syntactic regularities를 표현하고 있지만, '어떻게' 그 regularities를 얻어내고 있는지가 여전히 불명확한 상황에서 제시된 논문이다.
이 GloVe 라는 방법은 log-bilinear regression을 이용하는 모델로서, global matrix factorization과 local context window, 두 방법이 갖는 장점을 결합함으로써 이루어진다고 서술되어있다.
즉, 이 논문의 가장 중요한 부분을 풀어서 설명하면, 전체 corpus에서 단어 i, j가 동시에 등장하는(co-occur) 빈도 수를 기록한(실제 값은 아마 weighted 처리 되어있지만) co-occurence matrix X를 이용하기 때문에 '통계 기반 모델'의 특성을 가지고 있고, context word i와 주변 단어 j의 co-occur을 측정할 때의 window size를 설정하는 과정에서 'local context window' 를 사용하는 것과 같기 때문에, 두 모델의 장점을 결합한 방식의 word representation 학습 방법이라고 할 수 있는 것이다.
word2vec은 local context window를 사용했기 때문에, large corpus data안에서 통계를 사용하지 않았다는 점에서 해당 장점을 활용하지 못했다는 비교 단점이 존재한다.

(본인이 어려워했던 부분)
또한, 해당 논문은 word2vec의 CBOW, Skip-Gram과는 다르게 단어를 '예측' 하면서 loss 를 토대로 학습해나가는 과정이 아닌, 통계 기반으로 작성된 수식(Objective functions with X)을 토대로 학습해나가는 과정을 거친다. 다시, co-occurence matirx X는 맨 처음 corpus로부터 구해지는 행렬이며, 학습 과정에서는 수식을 통해 i, j를 iterate하면서 W, W tilda를 학습시킨다(W weight matrix로부터 얻어진 w, w tilda, 그리고 i, j에 대한 X 값을 기반으로 함.)
선행 기술
Matrix Factorization Method
대표적인 Matrix factorization method로는 LSA(Latent Semantic Analysis)와 HAL(Hyperspace Analogue to Language), 그리고 이를 보완한 COALS가 있다. low-dimensional word representation으로 의미를 추출하고자 하는 다소 고전적인 statistical method 들이 존재했다(LSA에 대한 보다 자세한 설명은 Word2Vec 논문을 리뷰한 페이지 참고. Matrix decomposition을 수행한 것.)
LSA와 HAL이 무의미한 단어의 반복 또한 count 한다는 단점을 극복하기 위해 COALS는 entropy, correlation 개념을 도입하였다.
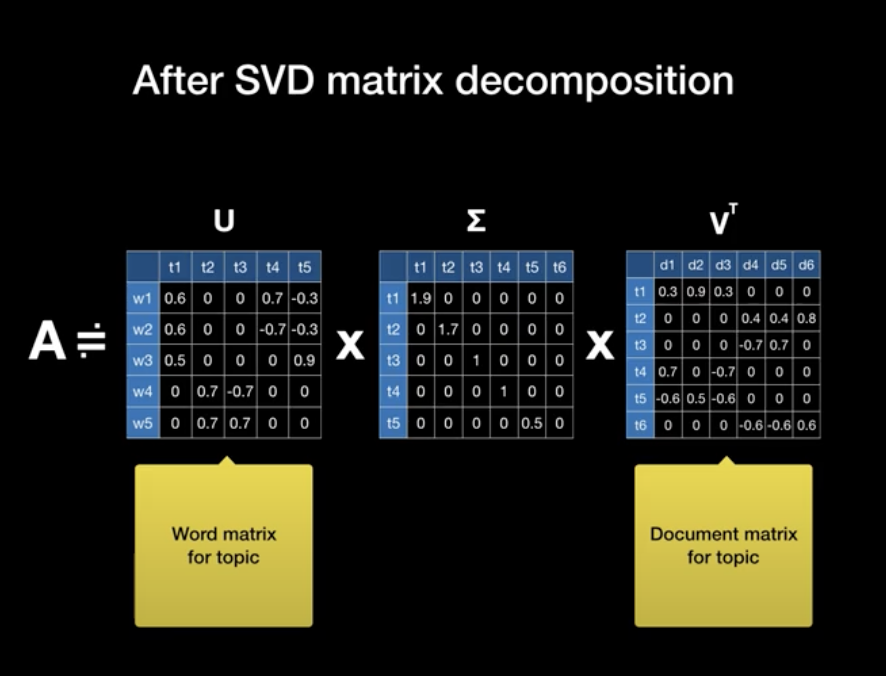
Shallow Window-Based Methods
word2vec에서 사용한 CBOW, Skip-Gram모델이 이런 형태이다.
논문에서 제시하는 모델 - GloVe
현재까지 제시된 word representation 관련 논문들은 단어가 등장하는 statistics로부터 어떻게 meaning이 추출되는지, 어떻게 word vectors가 해당 meaning을 표현하는지 매끄럽게 설명하지 못했다는 한계를 언급했다.
해당 논문은 GloVe: Global Vectors for Word Representation을 제시하며, 통계적인 자료로부터 word representation을 어떻게 나타낼 수 있는지에 대해서를 설명하고 있다.
논문 챕터 3. GloVe 파트를 요약하자면, 딥러닝 모델에서 학습하는 loss function을 어떻게 설계했는지를 수학적으로 매끄럽게(?) 설명해나가는 과정이 서술되어있다.
아래부터는 논문을 해석하며 천천히 이해해나간 과정이다. 건너뛰어도 무방하다.
수식적 표현(Objective function)
이 논문에서는 상당 부분을 수식적으로 표현하고 증명하는 데 소모했다. 모델의 목적함수가 어떤 과정으로 설계되었는지 이해하는 과정은 딥러닝 모델의 이해에 필수적이므로, 이해한 내용을 정리해보겠다.
특정 단어 i, j에 대한 co-occurence 횟수를 기반으로 전체 corpus 기반 co-occurence matrix X를 만들었다. 자주 함께(co-occur) 등장하는 단어는 연관성이 높다고 추측할 수 있기 때문에, 이러한 통계기반의 모델링을 진행하는 것이다.
특정 단어 i(논문에서는 context word라고 하였음)가 등장한 뒤 특정 단어 j가 등장할 확률은 X를 기반으로 Pij = P ... 로 나타낼 수 있다.
이를 기반으로 논문은 이 조건부확률 P를 모델링하기 위한 여정을 서술하고있다.
(논문의 4.2 파트에서 추가적으로 설명하였지만, co-occurence matrix X를 제작할 때, context window size(ex. 10)을 설정하여, 단어가 d 개수만큼 떨어진 경우 1/d 의 값을 weight로 한 'decreasing weighting function'을 설계하여 X를 제작하였다. 이러한 방식으로 멀리 떨어질 수록 덜 중요하다고 학습하도록 했으며, 기존 context window 방식의 학습 method의 장점을 가져왔다.)
연관있는 단어일 수록 등장확률이 높아지기 때문에, 이를 분수화 하면 word i에 더 연관이 있는지, word j에 더 연관이 있는지를 확인할 수 있게 된다(word i에 더 연관있다면 분자가 더 커지므로 1보다 훨씬 큰 값을 가지고, word j에 더 연관이 있다면 분모가 커지므로 0에 가까운 값을 가질 것이다)
word vector representation은, 따라서, 단어 자체의 등장 확률에 영향받는 방향 대신, 다른 단어와 co-occur하는 확률을 기반으로 학습되어야 함을 알 수 있다. 이를 모델링 하기 위해 논문은 함수 F를 제시하였다.
$$F\left(w_i, w_j, \tilde{w}_k\right)=\frac{P_{i k}}{P_{j k}}$$
함수 F를 특정할 수 있어야 궁극적으로 우리가 원하는 방식으로 word vector representation을 학습할 수 있다.
벡터 공간에서의 연산을 손쉽게 하기 위해서 vector representation의 difference를 - 연산으로 나타낼 수 있고,
수식의 우항은 스칼라 값이기 때문에 F 내부의 연산 값 또한 스칼라로 만들기 위해 아래와 같이 dot product로 나타낼 수 있다.
$$F\left(w_i-w_j, \tilde{w}_k\right)=\frac{P_{i k}}{P_{j k}}, F\left(\left(w_i-w_j\right)^T \tilde{w}_k\right)=\frac{P_{i k}}{P_{j k}}$$
여기서부터 조금 어려운데, 항등원에 대한 개념이 추가된다. 함수의 좌항을 우항과 연관시키기 위해서 진행한 것이다. 다시, context word i 와, 임의의 word k는 두 역할을 바꾸어도 해당 수식이 성립해야 한다. 즉, 치환이 가능해야 한다는 의미이다.
$$ w \leftrightarrow w^T, X \leftrightarrow X^T $$
해당 특성을 갖게 하기 위해서 F 함수를 더 변형시켜주는 과정을 계속 거치게 된다(model should be invariant under this labeling)
함수 내부에서의 덧뺄셈 연산을 함수 외부에서는 곱셈연산으로 치환하는 homomorphism F 의 개념을 도입한다. 덧셈 연산에 대해 함수 결과로는 곱셈이 되고, 뺄셈 연산에 대한 함수 결과는 나눗셈이 되도록 하는, F의 특성을 정의하면서 식은 아래와 같이 전개될 수 있게 된다.
$$F\left(\left(w_i-w_j\right)^T \tilde{w}_k\right)=\frac{F\left(w_i^T \tilde{w}_k\right)}{F\left(w_j^T \tilde{w}_k\right)}$$
위에서 제시한 homomorphism 특성을 만족하는 가장 간단한 함수는 exponential 함수이다. 따라서 F 를 전개하면 아래와 같이 정리된다.
$$w_i^T \tilde{w}_k=\log \left(P_{i k}\right)=\log \left(X_{i k}\right)-\log \left(X_i\right)$$
이 때, 우리는 symmetry를 유지하고 싶다고 했다. 다시말해서, context word i 에 대한 X_ij가 반대로 context word j 에 대해서도 동일한 수식적 결과가 나올 수 있도록, 설계하고자 한다. 이를 위해서 상수와 같은 값들을 b 로 치환하고 처리하면 아래와 같은 식으로 정리된다.
여기서 로그X_i는 명백하게 상수이기 때문에 상수 b로 치환할 수 있고, k에 대한 bias는, 교환법칙을 성립시키기 위해 임의로 집어넣은 항이다.
$$w_i^T \tilde{w}_k+b_i+\tilde{b}_k=\log \left(X_{i k}\right)$$
여기서 로그함수의 발산을 제거하기 위한 method로 여러가지가 제시될 수 있으나(LSA 에서 사용했던 factorizing the log 등), 이 접근 방식에서의 또 다른 문제 - 거의 동시에 등장하지 않는 단어들도 같은 가중치를 갖는다 - 를 같이 해결하고자 이 논문에서는 "weighted least squares regression model" 을 최종적으로 제시한다. GloVe 모델의 Objective function의 최종적인 형태는 아래와 같다.
$$J=\sum_{i, j=1}^V f\left(X_{i j}\right)\left(w_i^T \tilde{w}_j+b_i+\tilde{b}_j-\log X_{i j}\right)^2$$
논문에서는 이 아래로도 weighting function f에 대한 수식적 설명을 계속한다. 간단하다. f를 어떻게 설계해야할 지를 설명한다.
x가 0으로 수렴할 때, f에 로그제곱을 곱한 형태는 유한하되, f자체는 0으로 빠르게 수렴해야하며, non-decreasing해야하고, x자체보다는 상대적으로 작아서 frequent co-occurences 가 너무 커지지 않게 해야한다.
이러한 조건들을 다 만족시키는 f는 아래와 같게 된다.
$$f(x)=\left\{\begin{array}{cc}\left(x / x_{\max }\right)^\alpha & \text { if } x<x_{\max } \\ 1 & \text { otherwise }\end{array}\right.$$
Complexity of the model
전체 courpus size의 0.8제곱의 complexity 밖에 안 가진다는 것을 증명하는 챕터라고 요약할 수 있다.
궁극적으로 해당 논문은 Word2Vec과의 성능 비교에서 우위를 점한다고 얘기하고 싶어한다.
논문의 result 부분에서도 한번 더 언급이 되지만, 비교를 위해 몇 가지 가정이 제시되어 있다. GloVe 의 Complexity를 계산하기 위해 논문에서는 word co-occurence 의 분포를 power-law function으로 가정한다.(power-law: 멱급수, 한 수가 다른 한 수의 거듭제곱 형태로 나타나는 함수 형태) 일부 자주 등장하는 단어 쌍에 비해 다른 단어 쌍은 빈도가 낮으므로, 충분히 그럴듯한 가정이라고 여겨진다.
$$X_{i j}=\frac{k}{\left(r_{i j}\right)^\alpha}$$
해당 식을 바탕으로, 논문은 complexity를 계산해나간다.
즉, GloVe 방식은 co-occurence matrix X 에 complexity가 의존되는데, X의 대부분의 원소(약 75~95%)는 zero를 기록하였으므로, vocabulary size의 제곱 꼴에 비례하다고 볼 수 없으며, 전체 corpus size에 비례하여 matrix X 가 설계되지만, X의 원소 분포를 power-law function으로 가정하고 이들의 합을 generalized harmonic number H로 재 정리하면, norm of X는 기껏해야 corpus size의 0.8제곱의 복잡도를 가진다고 계산할 수 있게 된다.
실험 결과 및 의의
본인이 흥미를 느낀 부분
흥미로웠던 부분은 위에서도 언급했지만, 4.2 Corpora and training details 였다. 추가 후속 논문 필요 없이도, 이 논문의 해당 파트만을 보고 이 논문이 어떤 세팅에서 학습을 진행했는지 보다 자세하게 이해할 수 있는 파트였다.
4. 1 Evaluation methods
word analogy task에 대한 실험 수행은 word2vec에서 제시된 방식과 동일하게 수행되었다.
4.2 Corpora and training details
해당 논문은 Embedding Matrix W 와, Embedding Matrix W tilda를 학습하게 된다(파트 3에서 제시했던 목적함수에 따라). co-occurence matrix X가 symmetric 하다면, W와 W tilda 또한 동일해야 하나, neural network의 학습 특성 상 완전히 동일하게 학습될 수 도 없을 뿐더러, 학습 방식에 따라(unsymmetric window size) 다르게 학습될 수도 있어서, 해당 논문은 최종 embedding matrix를 W+W tilda 로 제시하였다(일종의 boosting 방식으로 작동하는 효과를 내어 더 나은 결과를 가져다주었다고 함)
추가적으로, context window의 사용 말고도 negative sampling을 진행했다고 한다.
4.3 Results
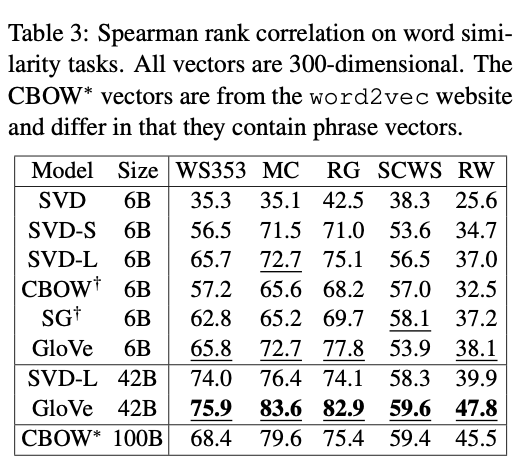
Word similarity task에서 Vocabulary size를 42B으로 설정하였을 때, 100B으로 학습한 Word2Vec의 CBOW 모델보다 월등한 성능 차이를 보였다. 또한, SVD-L에서 vocabulary size를 42B 으로 크게 키운것이 6B에서 학습한 결과보다 크게 scaled-up 되지 않은 것을 토대로, vocabulary에 대한 weighting function의 필요성을 반증하는 것이라고 논문은 주장하고 있다.
(확실히 lower relavant 한 information에 대한 제재는 필요한 것 같다)
4.4 ~ 4.7 Model Analysis: Vector Length, Context Size, Corpus Size, Run-time, Comparison with word2vec


해당 파트에서는 figure 2을 비롯해 다양한 성능 비교 figure, table에 대한 해석을 진행한다. Syntactic한 정보들은 보다 가까운 단어들에 위치하는 경향이 있으므로(ex. be p.p) context window size가 작을 때 syntactic acc가 semantic acc보다 높게 측정된 것을 확인할 수 있다. Semantic 정보는 보다 먼 단어에서도 유추할 수 있기 때문에, context window가 보다 넓을 때 acc 그래프가 역전 되는 것을 확인할 수 있다(non-local).
마찬가지로 Syntactic acc 는 corpus size 가 증가할 수록 높아지지만, semantic acc 는 학습하는 corpus의 특성에 크게 영향을 받는 것으로 나타났다.
5. Conclusion
궁극적으로 해당 논문에서 제시하는 GloVe는 해당 시기까지 제시된 다양한 task들에서 State-of-Art 성능을 나타내었다.
count-base로 global statistics 정보를 활용하고, 동시에 meaningful linear substructures 를 확인하는 장점을 보이며 word2vec보다 월등한 성능을 보인다고 주장하였다.
참고한 자료
1. https://nlp.stanford.edu/projects/glove/
2. https://aclanthology.org/D14-1162.pdf
3. https://www.youtube.com/watch?v=JZI74rrMb_M 고려대학교 산업경영공학대학원 논문리뷰 영상