* 현재 내용을 보충 및 수정 중인 포스트입니다.
논문의 저자
Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, Arnold Overwijk, Microsoft, 2021, ICLR
논문의 하이라이트 및 핵심
1. Dense Retrieval(DR)이 종종 Sparse Retrieval에 비해 성능이 낮게 나오는 이유를 밝혀냈다.
local uninformative negative samples들이 어떠한 영향을 주기 때문이다.
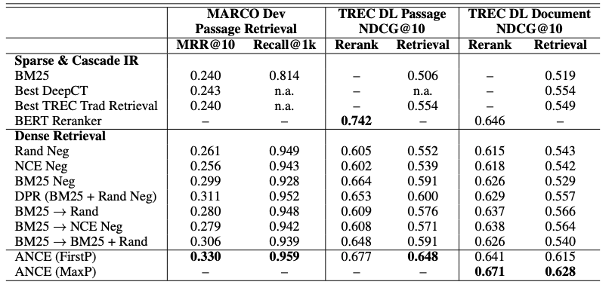
2.ANCE(Approximate nearest neighbor Negative Contrastive Learning)을 도입해서 BERT-base IR 과정에서 100배 효과적인 성과를 달성했다.
관련된 선행 연구
과거의 Open Domain Question Answering 시퀀스
Dense Retrieval(DR)
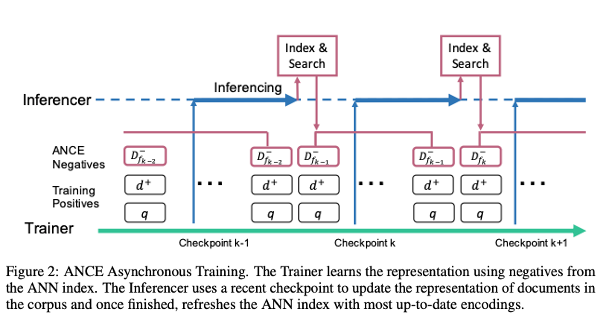
논문이 제시하는 모델 아키텍쳐
기존 Dense Retrieval에서 사용하는 Negative Sampling의 한계 극복
아이디어 1 - Convergence of Dense Retrieval Training

결국은, 밑의 두 항을 최소화 해야한다는 의미이다.
이전 논문들에 따르면, Gradient Norm을 크게하는 Sample이어야 두 항이 작아지게 된다.
아이디어 1 - Diminishing Gradients of Uninformative Negatives

결국 BERT layer 전체의 gradient 또한 0으로 수렴하게 되고,
이는 모델의 convergence를 방해하는 게 된다.
loss 가 작다는 것은 현재 알고 있는 것과 큰 차이가 없다는 것이니까.
아이디어 1 - Inefficacy of Local In-batch Negatives

Informative 한 optimal negative samples 는 전체 Context C에 비해 매우 적다고 가정할 수 있다.
따라서, mini-batch b에서 optimal negative sample을 가지고 있을 확률은 C의 제곱에 반비례하게 되고,
이는 거의 0에 수렴하게 되는데, 결국 이는 in-batch negative는 uninformative 하다고 해석할 수 있다.
아이디어 2 - Approximate Nearest Neighbor Noise Contrastive Estimation

FAISS는 대표적인 ANN 라이브러리이다. 즉, ANN 은 Nearest Neighbor를 탐색하는 데 걸리는 시간을 줄인 하나의 알고리즘.
실험 결과


결론
1. Dense Retrival 과정에서의 Representation Learning의 Convergence 에 대한 수학적인 분석을 수행하여 local negative과 왜 별 쓸모가 없는지 증명해 냄.
2. Local Negative Sampling의 Bottleneck을 제거하기 위한 ANCE 방법론을 고안해서 web search, OpenQA, Search Engine에서 효과적인 것을 확인.
여담1. 논문의 전체 페이지는 16쪽이지만, appendix와 reference를 제외하면 8쪽.
여담2. colbert는 related work에서 아주 간단히 언급된다(IR 단계에서 colbert 는 cashing으로 비용을 줄였으나 이 논문은~…)