논문의 저자
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, Open AI, 2018
논문의 하이라이트 및 핵심
1. Transformer의 디코더를 사용하였다.
2. 텍스트 데이터로부터 라벨이 없는 데이터를 만들어 Unsupervised learning으로 학습하였다.
3. specialized task를 수행할 때 다른 모델을 사용하지 않고, fine tuning 하기만 하면 되도록 하였다.
4. word tokenization에 sub-word tokenization 기법을 사용하였다.
5. 사전학습 과정과 특정한 태스크 수행을 위한 튜닝 과정에 상당히 많은 데이터세트가 필요하다.(데이터세트가 적으면 성능 큰 하락)
관련된 선행 연구
Semi-supervised Learning for NLP
이전 논문들에서 살펴보았던 Word Embedding 방식들(Word2Vec, Glove)은 라벨 없이 주변 단어로 학습하였기 때문에 Unsupervised-learning에 해당하였다. 이 워드 임베딩을 사용한 관련 연구들은, 특정 태스크에 대해 supervised learning을 수행해야 하기 때문에 비지도 + 지도 = 반지도 학습(Semi-supervised learning)으로 분류할 수 있다.
하지만 이 word embedding 방식은 word level information만을 학습하게 된다는 한계가 있어, higher level semantics를 이해하기 위한 phrase-level, sentence-level의 임베딩 방식도 연구되었던 바 있다.
Unsupervised pre-training
비지도학습은 반지도학습을 시작하기 위한 good initialization point를 찾는 것이 목표인 학습이다(적어도 이 논문에서는 그렇다)
먼저, Pre-training을 수행하는 것이 일종의 regularization과 비슷하게 동작하며, better generalization을 수행한다는 것이 증명되었던 바 있었다는 장점이 있다.
NLP에서도 따라서 이러한 Pre-training에 대한 연구가 진행되어왔다. Pre-training을 사용했고, supervised learning으로 Text Classification을 수행한 논문이 있었는데, 여기서 가장 주목할만한 방식은 LSTM을 사용했다는 점이다.
이 논문에서는 Transformer구조를 사용하여 longer linguistic structure에 대해 이해할 수 있다는 장점을 가져왔으며, 다양한 태스크를 수행할 수 있다는 점을 장점으로 꼽았다.
Auxiliary training object
딥러닝 모델을 설계할 때 Objective function을 잘 설계해야 모델이 데이터-라벨 쌍을 학습하고 원하는 '목적'을 달성할 수 있다.
NLP에서 이러한 보조적인 Unsupervised objective term을 설계하는 것은 semi-supervised learning으로 만들게 된다. POS 태깅, Named entity recognition등에 이러한 auxiliary training term을 두어 성능 향상을 본 논문이 있어 이 논문의 저자도 참고하였다.
논문이 제시하는 모델 아키텍쳐
Traning objective function
일반적인 NLP에서의 함수 모델링은 아래와 같이 수행할 수 있다. 이전까지 k개의 output(혹은 input)을 참고하여 현재 i번째 단어에 대한 확률을 조건부확률로 계산했다.

이 논문에서는 Transformer decoder를 사용하여 모델링을 진행한다. Input context token에 대해 position-wise feedforward를 수행한 뒤, multi-head self-attention을 수행하는 과정을 여러 번 거쳐 target token에 대한 distribution을 계산한다(소프트맥스)

즉, Transformer decoder를 이용하여 input sentence의 다음 word를 예측하는 것을 주된 Object로 삼는다(Pre-training)
알다시피, 논문은 이러한 Pre-training 모델에 이어 특정 태스크에 걸맞도록 Fine-tuning을 수행한다. 해당 과정은 supervised learning이며, 기 학습된 모델에서 나온 activation 결과 값 h를 새로운 Linear function의 input으로 삼는다. 이 과정을 정리하면 아래의 식과 같이 정리될 수 있다.

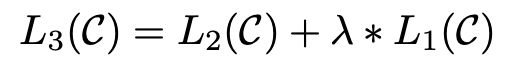
기존의 pre-training 모델에 추가적인 supervised learning을 수행하여, 전체적인 Obejective Function의 수식은 위와 같이 정리된다. 언급했다시피, 이러한 auxiliary objective term으로 인해 generalization 성능이 올라갔으며, 모델의 convergence가 가속화되었다고 한다.

참고로, pre-training 된 모델을 이용해서 여러가지 다른 태스크를 수월하게 수행하기 위해 논문 저자들은 위 그림의 right와 같이 input sentence에 대한 transformation을 수행해주었다. 문장 사이에 delimitor token 삽입, traversal-style appraoch 등을 수행했다고 한다(이전에 해당 태스크를 수행하는 다른 논문들에서 사용한 transformation을 채택하였음)
특이하게도 sentence similarity를 수행하기 위해 text1-text2 순서와 text2-text1 순서 두 개를 사용하였다.
실험 세팅
Pre-training을 위해서 BooksCorpus dataset, 1B Word Benchmark 데이터세트를 사용했다.
Task fine-tuning을 위해서는 각 task에 걸맞는 다양한 데이터세트로 학습을 수행하였다.

기타 모델 세팅 및 하이퍼 파라미터에 대한 설명들이 나열되어있으나, 생략하겠다.
특이한 점으로는, some punctuation에 대해서 standardize를 수행했다고 한다. dash('-'), punctuations('?', '!', '.' ...)를 어떠한 특정한 토큰으로 변환함으로써 raw text data를 '정제'했다고 표현하였다.
또한, Vocabulary를 만들기 위해서 Byte-pair Encoding 기법을 사용해 40,000 size of vocabulary를 만들었다.
결과 분석
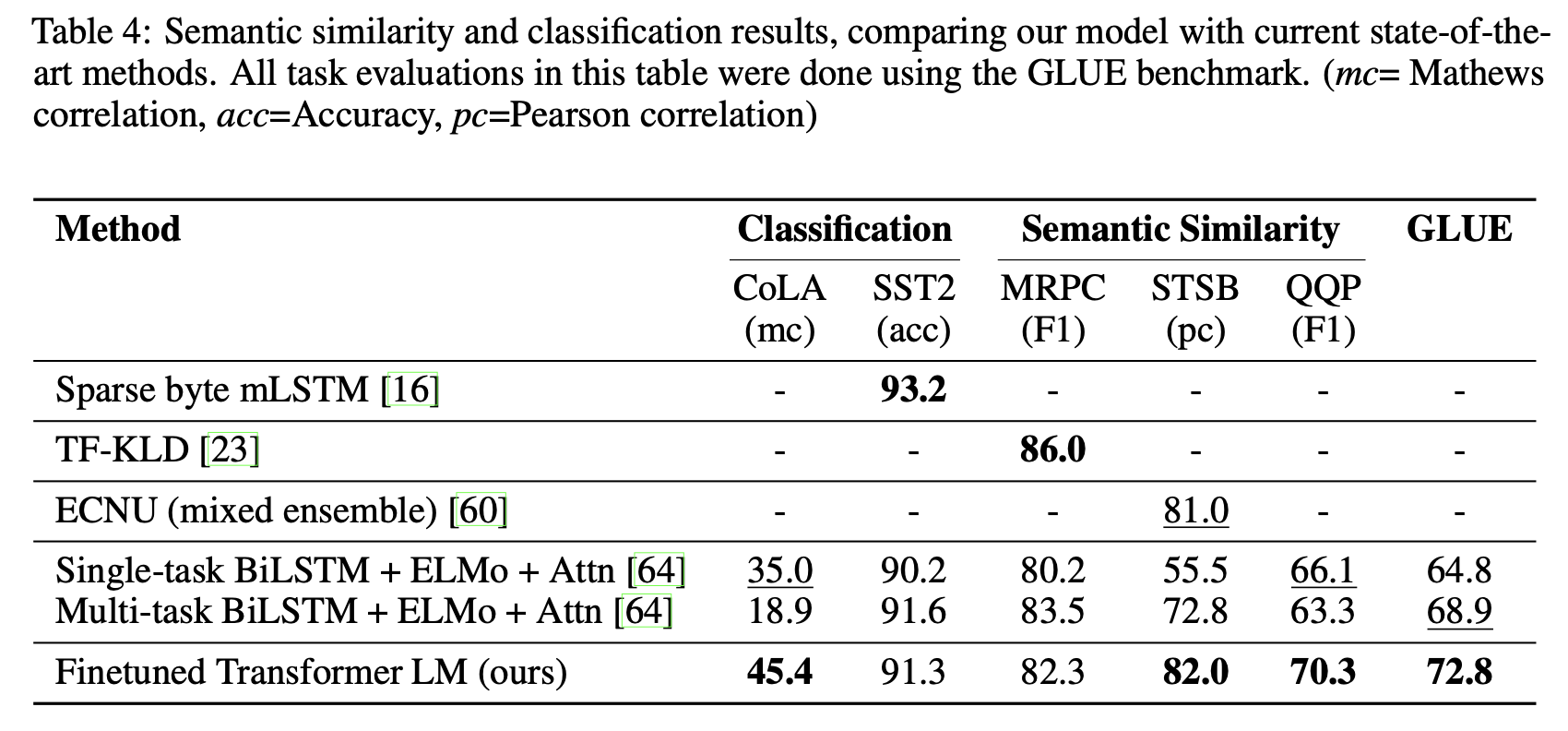
결과적으로 해당 논문의 모델, GPT-1은 12개의 Task dataset에서 기존 State-of-Art 모델들을 제치고 9개 dataset에서 신기록을 세웠다.
Impact of number of layers transferred

논문의 저자들은 다양한 분석을 시도했다. 첫 번째로, Figure 2 left에 해당하는 그림은, transformer decoder layer의 개수에 따른 Impact를 측정하고자 시도한 실험의 결과이다. 디코더 레이어(논문에서는 transferring embeddings 라고 언급함)의 개수가 증가할 수록 전체적인 퍼포먼스가 상승한다는 것을 볼 수 있었고, 특히 1개의 layer를 덧붙일 때마다 최대 9%의 성능 향상이 관측되었다고 한다(in MultiNLI 태스크)
Zero-shot Behaviors
Figure 2 right는 정말 pre-training + fine-tuning의 구조가 효과가 있는 것인지를 확인했던 결과이다. Pre-training만 수행한 뒤, 특정 태스크에 대해 모델을 전혀 학습하지 않고 pre-training update에 따른 퍼포먼스만 비교했다. 즉, zero-shot이란, 아무것도 변형을 주지 않은 채 얼마나 어떻게 행동하는지를 보는 것을 의미한다.
실선과 점선은 각각 transformer, LSTM에 대한 성능을 나타낸다. Transformer가 보다 task에 편향되지 않고 전반적으로 안정적이며 꾸준한 성능 향상을 보이는 것을(심지어 단순 LM에서) 확인하는 것에서, generative pre-training이 다양한 NLP 태스크 수행에 있어서 성능 향상을 이끌고, LSTM에 비해 transformer 구조가 Inductive bias가 적은 점이 장점으로 작용한다고 미루어 짐작할 수 있다.
* Inductive bias란 주어진 input으로부터 획득할 수 있는 어떠한 '유추할 수 있는 편향'으로, Linear Regression을 예로 들면, 주어진 인풋과 아웃풋은 선형관계에 있다고 추측할 수 있는 것이 'inductive bias'이다. Transformer는 이러한 사전적인 편향 정보를 학습하지 못한다는 것이 이러한 다양한 태스크 수행에 있어서는 큰 장점으로 작용한다.
Ablation studies
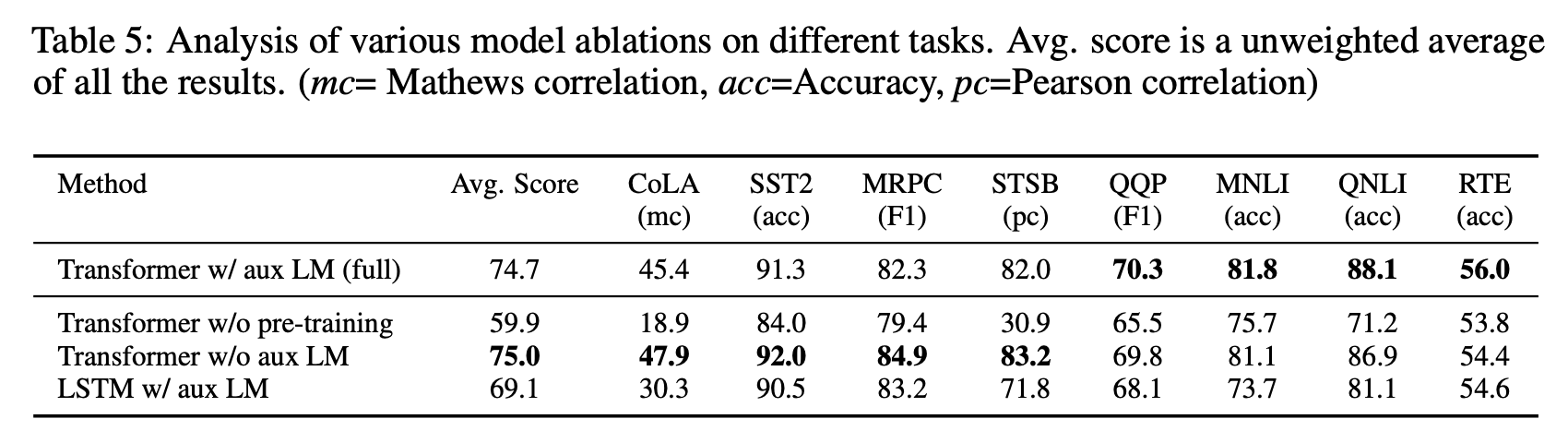
데이터세트 크기에 따라서 Objective function의 유무에 유의미한 성능 차이를 보이는지 확인한 실험이다.
전반적으로, 큰 데이터에스테 대해서는 auxiliary obejective 가 의미 있었다.
LSTM이 Transformer보다 전체적으로 낮은 성능을 보였으며, 무조건적으로 pre-training이 성능을 크게 향상시킨다는 것을 확인할 수 있었다.