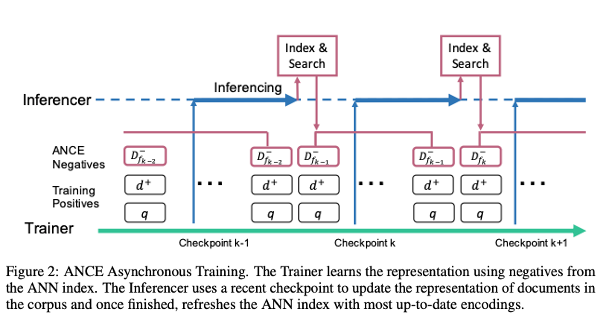
* 현재 내용을 보충 및 수정 중인 포스트입니다. 논문의 저자 Lee Xiong, Chenyan Xiong, Ye Li, Kwok-Fung Tang, Jialin Liu, Paul Bennett, Junaid Ahmed, Arnold Overwijk, Microsoft, 2021, ICLR 논문의 하이라이트 및 핵심 1. Dense Retrieval(DR)이 종종 Sparse Retrieval에 비해 성능이 낮게 나오는 이유를 밝혀냈다. local uninformative negative samples들이 어떠한 영향을 주기 때문이다. 2.ANCE(Approximate nearest neighbor Negative Contrastive Learning)을 도입해서 BERT-base IR 과정에서 100배..