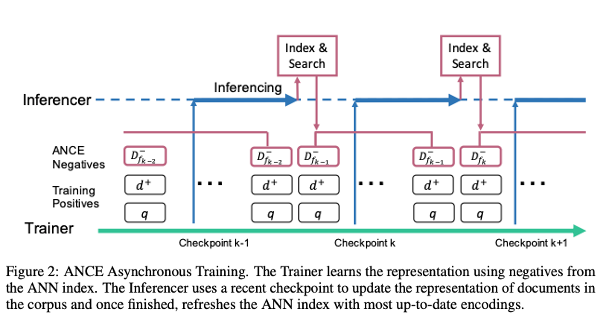
강화학습 오픈소스 코드들을 살펴보다가, 아래와 같은 이상한 코드를 발견한 적 있다.코드를 비동기함수로 동작시키는데, 무슨 코드를 어디로 보내는 것인지 싶었다.async def run_script(sbx: AsyncSandbox, script: str, language: str) -> float: execution = await sbx.run_code(script, language=language) try: return float(execution.text) except (TypeError, ValueError): return 0.0 except Exception as e: print(f"Error from E2B executor run_scrip..